
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构,不断的改善自身的性能。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。这些算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。简而言之,机器学习主要以数据为基础,通过大数据本身,运用计算机自我学习来寻找数据本身的规律,而这是机器学习与统计分析的基本区别。
机器学习主要有三种方式:监督学习,无监督学习与半监督学习。
(1)监督学习:从给定的训练数据集中学习出一个函数,当新的数据输入时,可以根据函数预测相应的结果。监督学习的训练集要求是包括输入和输出,也就是特征和目标。训练集中的目标是有标注的。如今机器学习已固有的监督学习算法有可以进行分类的,例如贝叶斯分类,SVM,ID3,C4.5以及分类决策树,以及现在最火热的人工神经网络,例如BP神经网络,RBF神经网络,Hopfield神经网络、深度信念网络和卷积神经网络等。人工神经网络是模拟人大脑的思考方式来进行分析,在人工神经网络中有显层,隐层以及输出层,而每一层都会有神经元,神经元的状态或开启或关闭,这取决于大数据。同样监督机器学习算法也可以作回归,最常用便是逻辑回归。
(2)无监督学习:与有监督学习相比,无监督学习的训练集的类标号是未知的,并且要学习的类的个数或集合可能事先不知道。常见的无监督学习算法包括聚类和关联,例如K均值法、Apriori算法。
(3)半监督学习:介于监督学习和无监督学习之间,例如EM算法。
如今的机器学习领域主要的研究工作在三个方面进行:1)面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统;2)认知模型,研究人类学习过程并进行计算模拟;3)理论的分析,从理论的层面探索可能的算法和独立的应用领域算法。
“关联规则”(Association Rules)是数据挖掘的主要技术之一,用于从庞大的数据库中寻找有用或有趣的模式和规则。关联规则最初产生于购物篮分析,它通过发现顾客放入其购物篮中不同商品之间的联系,分析顾客购买行为中隐含的有趣模式,从而指导销售商制订营销策略。单维关联规则特指只涉及单个属性项的关联规则。
设 I = { i1 , i2 ,..., im }是项的集合。设任务相关的数据D 是数据库事务的集合,其中每个事务T是项的集合,使得T ⊆ I。每一个事务有一个标识符,称作TID。设A 是一个项集,事务T 包含A当且仅当A ⊆ T。关联规则是形如A ⇒ B 的蕴涵式,其中A ⊂ I,B ⊂ I,并且A ∩ B =∅。规则A ⇒B 在事务集D 中成立,具有支持度s,其中s 是D 中事务包含A ∪ B(即A 和B 二者)的百分比。它是概率P(A ∪ B)。规则A ⇒ B 在事务集D 中具有置信度c,如果D 中包含A 的事务同时也包含B的百分比是c。这是条件概率P(B |A)。即 support (A ⇒ B ) = P(A ∪ B) confidence (A ⇒ B ) = P(B |A)
同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称作强规则。为方便计,我们用0%和100%之间的值,而不是用0 到1 之间的值表示支持度和置信度。项的集合称为项集。包含k 个项的项集称为k-项集。集合{computer, financial_management_software}是一个2-项集。项集的出现频率是包含项集的事务数,简称为项集的频率、支持计数或计数。项集满足最小支持度min_sup,如果项集的出现频率大于或等于min_sup 与D 中事务总数的乘积。如果项集满足最小支持度,则称它为频繁项集。频繁k -项集的集合通常记作Lk。关联规则的挖掘是一个两步的过程:
1. 找出所有频繁项集:根据定义,这些项集出现的频繁性至少和预定义的最小支持计数一样。
2. 由频繁项集产生强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度。
如果愿意,也可以使用附加的兴趣度度量。这两步中,第二步最容易。挖掘关联规则的总体性能由第一步决定。
二算法背景关联规则挖掘发现大量数据中项集之间有趣的关联或相关联系。随着大量数据不停地收集和存储,许多业界人士对于从他们的数据库中挖掘关联规则越来越感兴趣。从大量商务事务记录中发现有趣的关联关系,可以帮助许多商务决策的制定,如分类设计、交叉购物和贱卖分析。关联规则挖掘的一个典型例子是购物篮分析。该过程通过发现顾客放入其购物篮中不同商品之间联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。例如,在同一次去超级市场,如果顾客购买牛奶,他也购买面包(和什么类型的面包)的可能性有多大?通过帮助零售商有选择地经销和安排货架,这种信息可以引导销售。例如,将牛奶和面包尽可能放近一些,可以进一步刺激一次去商店同时购买这些商品。
 三相关应用
三相关应用
关联分类算法是继贝叶斯( Bayes) 、支持向量机( SVM) 等机器学习方法之后的又一重要分类技术,广泛应用于文本分类、Web文档分类、医学图像分类。经典的关联分类算法有CBA、CMAR、CPAR;
网络入侵检测技术作为防火墙技术强有力的助手,有效弥补了防火墙策略处理黑客攻击、信息窃取问题时出现的不足,成为网络安全监控系统可靠的保障。传统的入侵检测系统(IDS) 运用关联规则生成入侵检测标准规则库,通过判断网络数据与规则库的匹配度产生告警数据流。
隐私保护数据挖掘是指在数据挖掘的过程中通过采用数据干扰和查询限制的基本策略对原始数据进行保护,避免商业敏感数据、个人隐私数据泄露。
利用关联规则进行蛋白质结构预测,根据蛋白质序列的特点可以对这些序列数据进行量化和处理,再将关联规则算法用于序列数据集上寻找蛋白质序列中的关联关系。
随着遥感导航定位、地球物理等卫星数量的增加,空间地球大数据为地球科学研究带来新机遇。传统数据分析方法以统计分析、非线性拟合为主,其在处理多维、海量数据时存在明显不足。基于关联规则的挖掘模式可以揭示海洋、陆地、大气等地球数据之间的关系,从而推动全球变化、灾害科学领域的发展。
四参考资料1.数据挖掘与数据化运营实战,卢辉著,机械工业出版社(2016)
2. data mining Jiawei Han (机械工业出版社第三版)
3. Simon Haykin,《神经网络原理》,2004,机械工业出版社
4.百度
5.维基百科
五实例(数据挖掘概念与技术(韩家炜(第三版)))基于AllElectronics 的事务数据库。数据库中有9个事务,即 D= 9。Apriori 假定事务中的项按字典次序存放。我们使用下图解释Apriori算法发现D中的频繁项集。
| TID | List of item_ID's |
| T100 | I1,I2,I5 |
| T200 | I2,I4 |
| T300 | I2,I3 |
| T400 | I1,I2,I4 |
| T500 | I1,I3 |
| T600 | I2,I3 |
| T700 | I1,I3 |
| T800 | I1,I2,I3,I5 |
| T900 | I1,I2,I3 |
1. 在算法的第一次迭代,每个项都是候选1-项集的集合C1 的成员。算法简单地扫描所有的事务,对每个项的出现次数计数。
2. 假定最小事务支持计数为2(即,min_sup = 2/9 = 22%)。可以确定频繁1-项集的集合L1。它由具有最小支持度的候选1-项集组成。
3. 为发现频繁2-项集的集合L2,算法使用L1 L1 产生候选2-项集的集合C220。C2由2 L1 个2-项集组成。
4. 下一步,扫描D 中事务,计算C2 中每个候选项集的支持计数,如下图的第二行的中间表所示。
5. 确定频繁2-项集的集合L2,它由具有最小支持度的C2 中的候选2-项集组成。
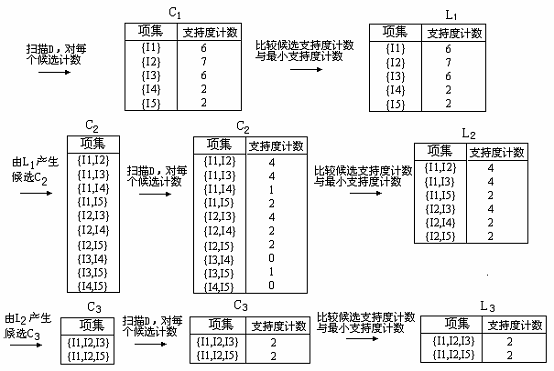
1.连接: C3= L2 L2={{I1,I2},{I1,I3},{I1,I5},{I2,I3},{I2,I4},{I2,I5}} {{I1,I2},{I1,I3},{I1,I5},{I2,I3},{I2,I4},{I2,I5}} ={{I1,I2,I3},{I1,I2,I5},{I1,I3,I5},{I2,I3,I4},{I2,I3,I5},{I2,I4,I5}} 2.使用Apriori 性质剪枝:频繁项集的所有子集必须是频繁的。存在候选项集,其子集不是频繁的吗? n {I1,I2,I3}的2-项子集是{I1,I2},{I1,I3}和{I2,I3}。{I1,I2,I3}的所有2-项子集都是L2 的元素。因此,保留{I1,I2,I3}在C3 中。 n {I1,I2,I5}的2-项子集是{I1,I2},{I1,I5}和{I2,I5}。{I1,I2,I5}的所有2-项子集都是L2 的元素。因此,保留{I1,I2,I5}在C3 中。 n {I1,I3,I5}的2-项子集是{I1,I3},{I1,I5}和{I3,I5}。{I3,I5}不是L2 的元素,因而不是频繁的。这样,由C3 中删除{I1,I3,I5}。 n {I2,I3,I4}的2-项子集是{I2,I3},{I2,I4}和{I3,I4}。{I3,I4}不是L2 的元素,因而不是频繁的。这样,由C3 中删除{I2,I3,I4}。 n {I2,I3,I5}的2-项子集是{I2,I3},{I2,I5}和{I3,I5}。{I3,I5}不是L2 的元素,因而不是频繁的。这样,由C3 中删除{I2,I3,I5}。 n {I2,I4,I5}的2-项子集是{I2,I4},{I2,I5}和{I4,I5}。{I4,I5}不是L2 的元素,因而不是频繁的。这样,由C3 中删除{I2,I3,I5}。 3.这样,剪枝后C3 = {{I1,I2,I3},{I1,I2,I5}}。
6. 候选3-项集的集合C3 的产生详细地列在图例中。首先,令C3 = L2,L2 = {{I1,I2,I3}, {I1,I2,I5},{I1,I3,I5}, {I2,I3,I4}, {I2,I3,I5}, {I2,I4,I5}}。根据Apriori 性质,频繁项集的所有子集必须是频繁的,我们可以确定后4个候选不可能是频繁的。因此,我们把它们由C3 删除,这样,在此后扫描D 确定L3 时就不必再求它们的计数值。注意,Apriori 算法使用逐层搜索技术,给定k-项集,我们只需要检查它们的(k-1)-子集是否频繁。
7. 扫描D 中事务,以确定L3,它由具有最小支持度的C3 中的候选3-项集组成。
8. 算法使用L3 ,L3 产生候选4-项集的集合C4。尽管连接产生结果{{I1,I2,I3,I5}},这个项集被剪去,因为它的子集{I1,I3,I5}不是频繁的。这样,C4 =∅,因此算法终止,找出了所有的频繁项集。
六输入输出输入要求:整数型。
输出结果:单维关联规则,列出频繁项集和强规则。
七相关条目频繁项集,支持度,置信度
八优缺点优点:
1. 可以产生清晰有用的结果;
2. 支持间接数据挖掘;
3. 可以处理变长的数据;
4. 它的计算的消耗量是可以预见的。
缺点:
1. 当问题变大时,计算量增长得厉害;
2. 难以决定正确的数据;
3. 容易忽略稀有的数据。


