
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构,不断的改善自身的性能。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。这些算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。简而言之,机器学习主要以数据为基础,通过大数据本身,运用计算机自我学习来寻找数据本身的规律,而这是机器学习与统计分析的基本区别。
机器学习主要有三种方式:监督学习,无监督学习与半监督学习。
(1)监督学习:从给定的训练数据集中学习出一个函数,当新的数据输入时,可以根据函数预测相应的结果。监督学习的训练集要求是包括输入和输出,也就是特征和目标。训练集中的目标是有标注的。如今机器学习已固有的监督学习算法有可以进行分类的,例如贝叶斯分类,SVM,ID3,C4.5以及分类决策树,以及现在最火热的人工神经网络,例如BP神经网络,RBF神经网络,Hopfield神经网络、深度信念网络和卷积神经网络等。人工神经网络是模拟人大脑的思考方式来进行分析,在人工神经网络中有显层,隐层以及输出层,而每一层都会有神经元,神经元的状态或开启或关闭,这取决于大数据。同样监督机器学习算法也可以作回归,最常用便是逻辑回归。
(2)无监督学习:与有监督学习相比,无监督学习的训练集的类标号是未知的,并且要学习的类的个数或集合可能事先不知道。常见的无监督学习算法包括聚类和关联,例如K均值法、Apriori算法。
(3)半监督学习:介于监督学习和无监督学习之间,例如EM算法。
如今的机器学习领域主要的研究工作在三个方面进行:1)面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统;2)认知模型,研究人类学习过程并进行计算模拟;3)理论的分析,从理论的层面探索可能的算法和独立的应用领域算法。
粗糙集理论是一种新的处理模糊和不确定性知识的数学工具。其主要思想是在保持分类能力不变的前提下,通过知识约简,导出问题的决策或分类规则。粗糙集分析方法中用到的数据类型为离散型数据,对于连续型数据必须在处理前离散化。
基本概念
定义1 一个信息系统是一个四元组,可表示为:
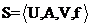
其中 为对象的非空有限集合;
为对象的非空有限集合; 为属性的非空有限集合;
为属性的非空有限集合; 为属性的值域集;
为属性的值域集;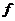 为信息函数,
为信息函数, 。如果
。如果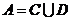 ,
, ,
, 为条件属性集,
为条件属性集,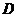 为决策属性集,则把信息系统称为决策系统,用
为决策属性集,则把信息系统称为决策系统,用 或
或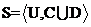 来表示,其中
来表示,其中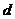 为单一的决策属性。从数据库的角度来看,决策系统就是一张表,其中
为单一的决策属性。从数据库的角度来看,决策系统就是一张表,其中 是记录集合,是字段集合,每一个对象对应一条记录,这样决策系统又可称为决策表。
是记录集合,是字段集合,每一个对象对应一条记录,这样决策系统又可称为决策表。
定义2 在决策系统中,对于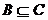 ,则B在U上的不可分辨关系定义为:
,则B在U上的不可分辨关系定义为: ,
, 把划分为
把划分为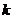 个等价类,
个等价类, ,
,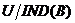 表示等价关系的所有等价类组成的等价类族,即有:
表示等价关系的所有等价类组成的等价类族,即有:  。
。
定义3 ,分类价 关于条件属性的正域(简称的正域)定义为:
关于条件属性的正域(简称的正域)定义为:

其中,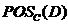 包含了中所有能被正确分类为
包含了中所有能被正确分类为 中一类的对象。在上的依赖度定义为:
中一类的对象。在上的依赖度定义为:

—个属性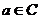 ,如果
,如果 ,则
,则 称为为可去除的;否则称为不可去除的。
称为为可去除的;否则称为不可去除的。
属性集 称为的一个约简,如果满足以下条件:
称为的一个约简,如果满足以下条件:
 ,
,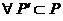
一个条件属性的约简是具有同相同分类能力的一个的子集,并且约简中的任意一个属性都不能在不降低其分类能力的前提下被删除。
粗糙集,1982年由波兰数学家Z.Pawlak首次提出。20世纪70年代,pawlak和波兰科学院、华沙大学的一些逻辑学家,在研究信息系统逻辑特征的基础上,提出了粗糙集理论的思想。
在最初的几年里,由于大多数研究论文是用波兰文发表,所以未引起国际计算机界的重视,研究地域仅局限于东欧各国。
1982年,Pawlak发表论文《Rough Sets》,标志该理论正式诞生
1991年,Pawlak的第一本关于粗糙集的理论专著《Rough sets:theoretical aspects of reasoning about data》;1992年,Slowinski主编的《Intelligence decision support :handbook of application and advances of rough sets theory》的出版,奠定了粗糙集理论的基础,有力地推动了国际粗糙集理论与应用的深入研究。
1992年,在波兰召开了第一届国际粗糙集理论研讨会,有15篇论文发表在1993年第18卷的《Foundation of computing and decision sciences》上。
三算法应用粗糙集理论能够提供有效的技术用于数据挖掘的数据预处理、数据缩减、规则生成、数据依赖关系发现等方面,故该理论目前作为数据挖掘领域的一种主流方法,也正受到越来越多研究者的关注,并开始被广泛应用于数据挖掘、机器学习、决策支持系统和模式识别等众多领域。粗糙集主要用于特征归约,能识别和删除无助于给定训练数据分类的属性,提炼出重要属性和约简属性集。
四参考资料1. 基于不完备信息系统的粗糙集方法及应用实例,郭秀峰,郭小娟,大连名族学院学报,2006(Ⅰ)
2. data mining ,Jiawei Han (机械工业出版社第三版)
3. Simon Haykin,《神经网络原理》,2004,机械工业出版社
4. 维基百科
五实例表1给出了8套商品房的一些信息, 其中有些信息是不完备的, 我们需要从中做出选择.因为有些信息不完备, 可能还是比较重要的信息,所以不能完全根据给出的一些信息作为我们决策的标准。在这里就运用粗糙集的理论做出一个最优选择的队列.这8套商品房的信息见表1 ,其中的L、P 、T 、E 、S 、A 分别代表楼层、价格、交通、环境、面积、房屋结构;

注:表格中的属性值是根据各套房子关于各属性的优劣程度给出的, 数字越大就表明越好.*表示属性值不清楚或难以确定。
为了直观并简化计算, 我们可以先将这8套商品房的属性值用Low和High来表示。这样就可以将选择的范围大大地缩小, 在此基础上加上决策属性, 作出表2。

从表2 知:
U = {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8},AT = {L , P , T , E , S , A};U
SIM (AT ) = {SAT (1), SAT (2), SAT (3),SAT (4), SAT (5), SAT (6), SAT (7), SAT (8)},
其中:
SAT (1) = {1 , 5 , 7}, SAT (2) = {2 , 7},SAT (3) = {3 , 8}, SAT (4) = {4}, SAT (5)= {1 , 5 , 8}, SAT (6) = {6}, SAT (7) ={7}, SAT (8) = {3 , 5 , 8},U/ ind (d) = {Xgood , Xpoor , Xexcel }, 其中,Xgood = {1 , 4 , 5 , 7}, Xpoor = {3 , 6 , 8},Xexcel = {2}.因此 = {1 , 4};
= {1 , 4};  = {1 , 2 , 4 , 5 , 7 , 8};
= {1 , 2 , 4 , 5 , 7 , 8};  = {3 , 6};
= {3 , 6};  = {3 , 5 , 6 , 8};
= {3 , 5 , 6 , 8}; =∅;
=∅;  = {2 , 6 , 7};
= {2 , 6 , 7};
我们可以得到广义决策表(见表3)

U/ ind (d) = {Xpoor , Xgood , Xpoor , good , Xgood , excel},
其中Xgood = {1 , 4},
Xpoor = {3 , 6}, Xpoor , good = {5 , 8},Xgood , excel = {2 , 7}.
因此:
= {4}; = {1 , 4 , 5 , 7};
= {6}; = {3 , 6 , 8};
 =Υ;
=Υ; = {1 , 3 , 5 , 8};
= {1 , 3 , 5 , 8};
 = {2};
= {2}; = {1 , 2 , 7}.
= {1 , 2 , 7}.
至此, 我们就可以对上面的8套商品房做出挑选。假设2号商品房可能是最优的, 但是因为某一个原因, 例如价格, 我们放弃了2号商品房;然后我们可以在1号和7号商品房中选择.经过粗糙集理论的处理, 我们对这8套商品房进行了重新分类, 由原先的Poor 、Good 、Excel 变成了{poor }、{poor good }、{good }、{good,excel }, 且做出了这些分类上下近似集, 这样就更利于我们的决策。
六输入输出√ 输入变量类型:数值型。
→ 输出结果:
√ 重要属性集:列出决策表中的核值。
√ 约简属性集:列出决策表中的核值和用户指定属性。
√ 约简表:列出决策表中的核值、用户指定属性和对应的决策属性
√ 决策规则:列出记录的分类结果。
七相关条目信息函数,模糊,信息系统
八优缺点主要优点:
1. 除数据集外,无需任何先验知识(或信息)
2. 对不确定性的描述和处理相对客观
局限:
1. 缺乏处理不精确或不确定原始数据的机制
2. 对含糊概念的刻画过于简单
3. 无法解决所有含糊的、模糊的不确定性问题


