
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构,不断的改善自身的性能。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。这些算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。简而言之,机器学习主要以数据为基础,通过大数据本身,运用计算机自我学习来寻找数据本身的规律,而这是机器学习与统计分析的基本区别。
机器学习主要有三种方式:监督学习,无监督学习与半监督学习。
(1)监督学习:从给定的训练数据集中学习出一个函数,当新的数据输入时,可以根据函数预测相应的结果。监督学习的训练集要求是包括输入和输出,也就是特征和目标。训练集中的目标是有标注的。如今机器学习已固有的监督学习算法有可以进行分类的,例如贝叶斯分类,SVM,ID3,C4.5以及分类决策树,以及现在最火热的人工神经网络,例如BP神经网络,RBF神经网络,Hopfield神经网络、深度信念网络和卷积神经网络等。人工神经网络是模拟人大脑的思考方式来进行分析,在人工神经网络中有显层,隐层以及输出层,而每一层都会有神经元,神经元的状态或开启或关闭,这取决于大数据。同样监督机器学习算法也可以作回归,最常用便是逻辑回归。
(2)无监督学习:与有监督学习相比,无监督学习的训练集的类标号是未知的,并且要学习的类的个数或集合可能事先不知道。常见的无监督学习算法包括聚类和关联,例如K均值法、Apriori算法。
(3)半监督学习:介于监督学习和无监督学习之间,例如EM算法。
如今的机器学习领域主要的研究工作在三个方面进行:1)面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统;2)认知模型,研究人类学习过程并进行计算模拟;3)理论的分析,从理论的层面探索可能的算法和独立的应用领域算法。
协同过滤算法的主要功能是预测和推荐。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based CF),和基于物品的协同过滤算法(item-based CF)。
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对物品喜爱程度,并对这些喜好进行度量打分。通过不同用户对商品态度和偏好程度计算用户之间的关系,对有相同喜好的用户间进行商品推荐。
基于物品的协同过滤算法是通过计算不同用户对不同物品的评分获得物品间的相关关系。基于物品间的相关性对用户进行相似物品的推荐。
相似性度量标准:常用的相似性度量标准采用欧几里德距离和皮尔逊相关系数。
欧几里德距离:
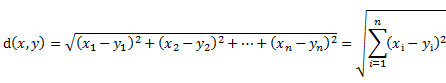
皮尔逊相关系数:
 二算法背景
二算法背景
1992年,Xerox公司为了解决研究中心资讯过载问题,最先将早期的协同过滤算法设计成一个名为Tapestry系统,该系统应用于解决员工处理邮件分类问题。
1994年,又一个基于协同过滤算法的系统GroupLens,该系统主要应用于新闻的筛选。与Tapestry不同,该系统是跨点、跨系统的新闻过滤机制,而Tapestry专指一个点的过滤机制;同时GroupLens会将同一笔资料从不同使用者得到的评分加总。
电子商务的推荐系统的发展。最著名的当属亚马逊网络书店。以上三个是协同过滤算法发展的重要里程碑,从早期的单一系统内的邮件、文件过滤,到跨系统的新闻、电影、音乐过滤,乃至如今的互联网的电子商务。
三相关应用协同过滤算法的主要功能是预测和推荐。经常被用来分辨某位特定顾客可能感兴趣的东西,并给他推荐相应的产品,而这些结论主要来自于对其他相似顾客对哪些产品感兴趣的分析。协同过滤以其出色的速度和健壮性,广泛应用于互联网等领域。
四参考资料1 Linden G, Smith B, York J, Amazon. Com recommendation item-to-item collaborative filtering [J]. IEEE computer society, 2003(1-2):76-80.
2黄萱菁,夏迎炬,吴立德.基于向量空间模型的文本过滤系统[J].软件学报,2003,14(3):435-442.
3邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004,25(9):1665-1670.
五实例下面主要以一个示例数据验证基于用户的协同过滤算法。假设有如下电子商务评分数据,想要预测用户C对商品4的评分
用户 商品1 商品2 商品3 商品4 用户A 4 ? 3 5 用户B ? 5 4 ? 用户C 5 4 2 ? 用户D 2 4 ? 3 用户E 3 4 5 ?
表中?表示未知评分。
首先,根据基于用户的协同过滤算法,要计算用户C对商品4的评分,其步骤如下所示:
(1)寻找用户C的邻居
从数据集中可以发现,只有用户A和用户D对商品4评过分,因此能够选择的候选邻居只有两个,分别为用户A和用户D。用户A的平均评分为4,用户C的平均评分为3.667,用户D的平均评分为3。
根据皮尔逊相关系数公式来看,首先计算用户C和用户A的相似度,因为两个用户都对商品1和商品3进行了评分,所以它们之间的相似度为:
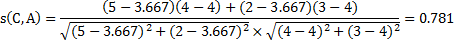
再次计算用户C与用户D的相似度,这两个用户都对商品1和商品2进行了评分,所以它们之间的相似度为:s(C,D)=-0.515.
(2)预测用户C对商品4的评分
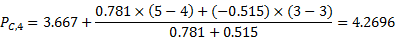
所以用户C对商品4的评分为4.2696。同理可以计算其它未知的评分。
六输入输出输入数据类型:数值型、字符型数据
输出结果:计算用户对商品的得分及相似度
七相关条目基于用户、基于物品、距离
八优缺点优点:能够过滤基于内容的机器难以进行分析的信息;能对一些复杂、难以表达的概念进行过滤;推荐的新颖性。
缺点:存在稀疏性问题,如用户对商品的评价特别少,使得基于用户评价的用户间相似性计算可能不够准确;随着用户和商品的增多,系统的性能会越来越低;存在最初评价问题,即没有用户对某一商品加以评价,则这个商品便不能被推荐。


