
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构,不断的改善自身的性能。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。这些算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。简而言之,机器学习主要以数据为基础,通过大数据本身,运用计算机自我学习来寻找数据本身的规律,而这是机器学习与统计分析的基本区别。
机器学习主要有三种方式:监督学习,无监督学习与半监督学习。
(1)监督学习:从给定的训练数据集中学习出一个函数,当新的数据输入时,可以根据函数预测相应的结果。监督学习的训练集要求是包括输入和输出,也就是特征和目标。训练集中的目标是有标注的。如今机器学习已固有的监督学习算法有可以进行分类的,例如贝叶斯分类,SVM,ID3,C4.5以及分类决策树,以及现在最火热的人工神经网络,例如BP神经网络,RBF神经网络,Hopfield神经网络、深度信念网络和卷积神经网络等。人工神经网络是模拟人大脑的思考方式来进行分析,在人工神经网络中有显层,隐层以及输出层,而每一层都会有神经元,神经元的状态或开启或关闭,这取决于大数据。同样监督机器学习算法也可以作回归,最常用便是逻辑回归。
(2)无监督学习:与有监督学习相比,无监督学习的训练集的类标号是未知的,并且要学习的类的个数或集合可能事先不知道。常见的无监督学习算法包括聚类和关联,例如K均值法、Apriori算法。
(3)半监督学习:介于监督学习和无监督学习之间,例如EM算法。
如今的机器学习领域主要的研究工作在三个方面进行:1)面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统;2)认知模型,研究人类学习过程并进行计算模拟;3)理论的分析,从理论的层面探索可能的算法和独立的应用领域算法。
1.1 算法摘要
利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies,BIRCH)算法是一种层次聚类算法,主要应用于对样本数据进行聚类。由于引入簇结构,能够客服一般聚类的不可伸缩性和扩展性,使得该聚类方法在大型数据库中取得良好的速度和伸缩性。
Birch算法既能对大规模数值数据进行聚类,又能够有效地处理离群点。Birch算法只需扫描一遍数据库就可以得到一个好的聚类效果,而且不需事先设定聚类个数,克服了K-Means算法需要预先设定聚类中心点个数的缺点。
BIRCH算法的特点:1)试图用可用的资源生成最好的聚类结果;2)采用多阶段聚类技术;3)是一种增量的聚类方法,因为对每个数据点的聚类的决策是基于当前已经处理过的数据点,而不是基于全局的数据点;4)只对球形的簇状结构能起到很好的作用。
1.2 算法原理
BIRCH聚类是通过聚类特征树(Cluster Feature-Tree)实现的,在一定程度上保存了对数据的压缩。通过引入聚类特征和聚类特征数来概括簇,这种簇结构使得该方法在大型数据库中取得好的速度和伸缩性,对对象的增量和动态聚类也非常的有效;由于Birch算法使用半径或直径的概念来控制簇的边界,比较适合球形的簇,如果簇不是球形的,则聚簇的效果将受到影响。
该算法在进行聚类时,一般包含两个步骤:1)单遍扫描数据,建立一颗存放于内存的初始CF树;2)采用某个选定的聚类算法对CF树的叶节点进行聚类,把稀疏的簇作为异常点删除而把稠密的簇合并为更大的簇。
一般的簇的质心X0,半径R和直径D可如下定义:
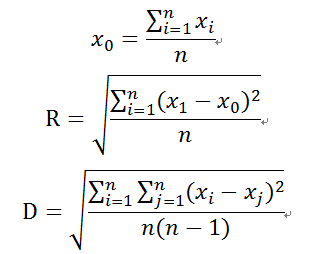
其中R是对象到质心的平均距离,D是簇中成对的平均距离。R和D都反映了质心周围簇的紧凑程度。
二算法背景BIRCH算法是由Tian Zhang于1996年提出来的,主要用来对大量数值数据进行聚类,该算法首先用树结构对对象进行层次划分,其中叶节点或者低层次的非叶节点可以看作是由分辨率决定的“微簇”。然后使用其他的聚类算法对这些微簇进行宏聚类。
三相关应用Brich算法已经在实际领域中得到广泛的应用,包括市场研究、模式识别、数据分析和图像处理。在商务中,可以用来发现不同的顾客群,刻画顾客的特征;在生物学中,能够用来推到动植物分类等。
四参考资料1 BIRCH:An Efficient Data Clustering Method for Very Large Databases.
2 Guha S, Mishra N, Motwani R, et al. Clustering data streams[C].Proceedings of FOCS 2000, 2000: 359-366.
3 Ordonez C. Clustering binary data streams with K-means[C].Proceedings of DMKD’03, June 13, 2003: 12-19.
五实例BIRCH算法的核心在于计算聚类特征(CF)及生成聚类特征树这两个部分。聚类特征是一个三维向量,汇总了对象簇的信息。它是BIRCH增量聚类算法的核心,CF树中的节点都是由CF组成,CF的定义如下:CF=(N,LS,SS),其中N是子类节点的个数,LS是N个节点的线性和,SS是N个节点的平方和。
假设簇C1中有三个数据点:(2,3),(4,5),(5,6),则
CF1={3,(2+4+5,3+5+6),(22+42+52,32+52+62)}={3,(11,14),(45,70)}
假定簇C1和簇C2是不相交的,其中CF2={3,(35,36),(417,440)}。C1和C2合并形成一个新的簇C3,其聚类特征计算为:
CF3=CF1+CF2={3+3,(11+35,14+36),(45+417,70+440)}={6,(46,50),(462,510)}
聚类特征树的结构类似于一颗B树,它有两个参数:分枝因子B和簇半径阈值T。分枝因子定义了每个非叶节点子女的最大数目,而阈值参数给出了存储在树的叶节点中子簇的最大直径。这两个参数直接影响着结果树的大小。一般的CF树的构建算法如下:
1)从根节点开始,自上而下选择最近的子节点
2)到达叶子节点后,检查最近元祖CFi能否吸收此数据点
是,更新CF值
否,是否可以添加一个新的元祖
是,添加一个新元祖
否,分裂最远的一对元祖,作为种子,按最近距离从新分配其他元祖
3)更新每个非叶节点的CF信息,如果分裂节点,在父节点中插入新的元祖,检查分裂,直到根节点为止。
六输入输出输入变量类型:数值型
输出结果:给出最终的聚类结果
七相关条目聚类、树结构
八优缺点优点:节省内存空间,计算速度加快;可识别噪声点
缺点:结果依赖于数据点的插入顺序;对非球状的簇聚类效果不好;算法在计算过程中一旦中断,一切必须从头再来;算法的局部性导致有可能出现聚类效果欠佳。


