
在处理数据之前,需要建立面板数据,导出生成数据并保存;建立面板数据时需要设置时间变量中的起始和终止时间,确定截面和变量,之后可以点击“生成文件”,进入输入数据的界面,创建好面板数据;本文以“面板数据分析”为例说明马克威软件的操作;案例分析了面板数据中的描述性统计量和面板数据分析两个方面。
(1)首先,在工作区,打开建模分析工作流“高级统计”→“面板数据模型”;
(2)然后连接数据源;
(3)然后进行参数设置
(4)双击运行按钮。
数据源为1996-2002年中国东北、华北、华东15个省及地区的居民家庭人均消费(不变价格)和人均收入数据。以“马克威通用数据2.mkw”为例,用户实例中GDP、二手房住宅价格指数、CPI、新建住宅价格指数、货物运输量为分析数据。(资料来源:《中国统计年鉴》1997-2003)。
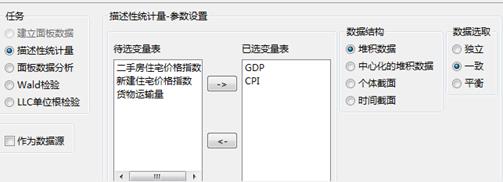
(1)选择变量参数
选择“训练”功能;其中各参数变量的说明如下:
已选变量表:待分析的变量列表;
数据结构:
堆积数据:对面板数据分析,按变量维度输出结果;
中心化的堆积数据:将整个面板数据进行个体中心化分析,按变量维度输出结果;
个体截面:分别对每个个体截面进行分析;
时间截面:分别对每个时间截面进行分析;
数据选取:
独立:每个变量的缺失对其他变量统计量的计算不产生影响;
一致:若某个变量有缺失,其他变量的对应位置也按缺失处理;
平衡:若某个变量有缺失,将每个个体的对应位置所在的时间截面按缺失处理。
设置好参数如下所示:
首先,由于面板数据结构的特殊性,系统允许用户通过“面板数据模型”节点新建数据作为数据源:
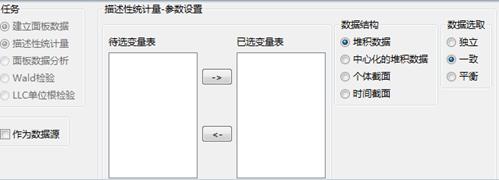
然后点击左下角“作为数据源”,进入下表格式:
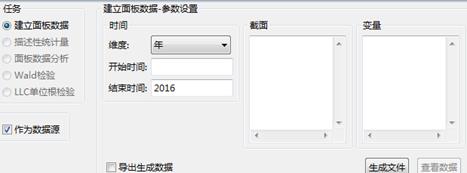
接着设置“开始时间”、“结束时间”,点击“导出生成数据”,设置好保存路径,设置和变量,显示界面如下所示:
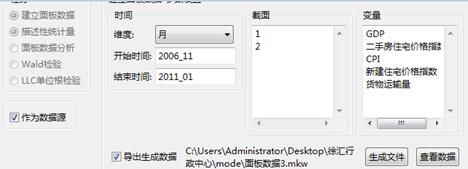
然后点击“生成数据”,将数据粘贴到对应栏,保存即可:
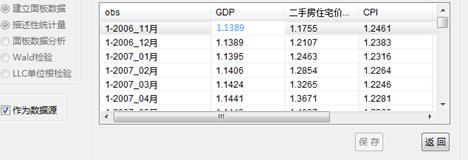
最后,根据生成的数据源重新导入到模型中,参数设置具体如下:
(2)点击运行节点,输出结果:
描述统计表:

(3)结果说明:
从描述统计表中可以观测到堆积数据的均值、中位数、最值、标准差、偏度、峰度、P值等统计量。
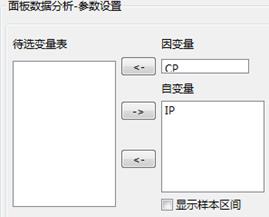
(1)选择“面板数据分析”选项,界面切换到相应设置,设置相应的参数,运行得到结果,其中各参数的说明如下:
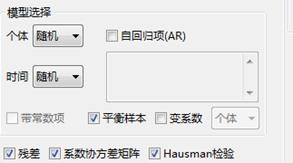
模型选择:
个体:指定个体效应的类型,包括“无”、“固定”和“随机”。
时间:指定时间效应的类型,包括“无”、“固定”和“随机”。注:当截面和时间效应都选“无”时,表示该模型为混合模型。
变系数:指定变系数模型的类型,包括“个体”和“时间”。选“个体”表示系数随横截面上个体而改变的模型;选“时间”表示系数随时间而改变的模型。
自回归项:指定自回归模型的自回归项,各项以逗号或空格分隔。
平衡样本:指定对非平衡面板数据缺失值的处理方式。
带常数项:指定混合模型是否包含常数项。
残差:选择后将在结果窗口中输出残差表、残差的协方差矩阵和相关系
数矩阵。
系数协方差矩阵:选择后将在结果窗口中输出系数的协方差矩阵。当模
型为固定效应模型和自回归模型时,不输出常数项的协方差矩阵。
Hausman检验:Hausman检验作为随机效应模型的输出结果,用于指定面
板数据回归模型的设定问题。在拒绝零假设时,模型设定为固定效应模型是可行的否则不能拒绝零假设,模型应设定为随机效应模型。
显示样本区间:选择要分析的样本区间,支持连续区间和非连续区间。
设置好参数如下所示:
(2)输出结果:
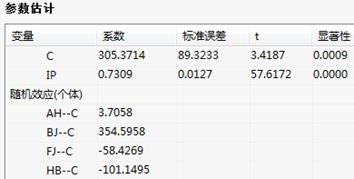
参数估计:
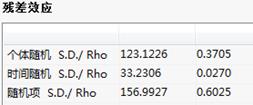
残差效应:
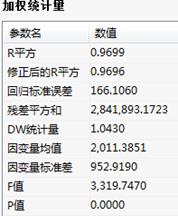
加权统计量:
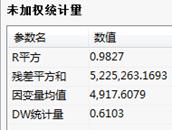
未加权统计量:
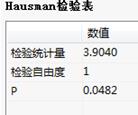
Hausman检验表:
(3)结果说明:
参数估计表中,给出了参数的估计值,包括系数值、系数的标准误差和显著性检验的t统计量及其P值、个体随机(固定)效应和时间随机(固定)效应。变系数模型将按照每个个体(或时刻)来输出其参数估计值;
残差效应表中,给出了误差分解的各项标准差(S.D.)及其方差所占总误差的方差的百分比(Rho),该项结果只有做随机模型时输出;
加权统计量表中,给出了加权系数模型的相关统计量,包括检验模型总体拟合优度等统计量,该项结果只有做随机模型时输出;
未加权统计量表中,给出了未加权系数模型的相关统计量,包括检验模型总体拟合优度等统计量;
Hausman检验表中,给出了渐近服从卡方分布的统计量、自由度及其统计量的P值;该项结果只有做随机模型时输出。
输入变量类型:要求数值型变量;如:整型、浮点型
面板数据模型用于处理时间和截面空间上取得的二维数据;这种数据从横轴上看,是由若干个体在某一时刻构成的截面记录值,从纵轴上看是个时间序列数据。而且面板数据模型还可以处理非平衡面板数据,即:面板数据中缺少了某些横截面的一些数据。
面板数据模型可以应用在计量经济学领域中,主要用来描述时间序列数据中自变量与因变量的回归关系。
面板数据模型能够处理时间序列的二维数据模型,选择合适的模型,能构对时间序列数据进行回归分析。
进行面板数据处理的原理可以归结为:
1)用单位根检验分析数据的平稳性。
经济时间序列的数据往往具有平稳和非平稳类型,而面板数据模型分析的前提是序列具有平稳性,如果对非平稳数据处理,可能会得到伪回归的情况。所以可对面板数据进行LLC单位根检验,单位根不存在则序列平稳,否则要先对数据做差分,使其平稳。在检验时可以先对面板序列数据绘制时序图,观察时序图中由各个观测值描绘出代表变量的折线是否含有趋势项和截距项,从而为单位根检验模式做准备。
2)协整检验或模型修正。
如果发现变量之间是同阶单整的,可用协整检验考察变量之间长期的均衡关系;若果经过单位根检验发现变量之间是非同阶单整的,可在不改变变量经济意义的前提下,对数据进行差分化,消除数据不平稳对回归造成的不利影响。
3)面板模型的选择与回归。
面板数据模型的选择通常包含三种形式:混合估计模型、固定效应模型和随机效应模型。其中混合效应模型的斜率项和截距项都是相同的,可用最小二乘法估计参数;固定效应和随机效应模型的斜率项相同,但截距项不同,可以在模型中添加虚拟变量的方法估计参数。随机效应模型是在截距项中包含了截面随机误差项和时间随机误差项的固定效应模型。
可以用F检验决定选用混合模型还是固定效应模型,然后用Hausman检验确定用随机效应模型还是固定效应模型。
输出结果:
参数估计:给出变量的系数、标准误差、T统计量和显著性P值;
残差效应:给出个体随机、时间随机和随机项;
加权统计量:给出加权的各类统计量;如:R平方、修正的R平方、回归标准误差、F值和P值等;
未知加权统计量:给出未加权系数模型的相关统计量;
方程估计:按每个个体给出了估计方程;
方程(代入参数值):按每个个体给出了估计方程;
残差表:给出所有面板数据的残差;
系数的协方差矩阵:按每个个体或时刻输出其系数协方差矩阵;
Hausman检验表:给出了渐近服从卡方分布的统计量、自由度及其P值。该项结果只有做随机模型时输出。
| 订购用户 | 订购时间 | 年限 | 运行环境 | 版本 |
| 1358****950 | 2023-05-01 00:02:26 | 1年 | Windows | 单机版 |
| 1358****950 | 2023-04-30 23:44:59 | 1年 | Windows | 单机版 |
| 1358****950 | 2023-04-30 23:36:14 | 1年 | Windows | 单机版 |
| 1522****265 | 2021-10-08 15:15:10 | 1年 | Windows | 单机版 |
| 1375****352 | 2019-01-12 15:16:50 | 1年 | Windows | 单机版 |
| 1811****398 | 2018-07-23 13:48:09 | 1年 | Windows | 单机版 |
| 1864****834 | 2018-07-23 11:42:52 | 1年 | Windows | 单机版 |
| 1864****834 | 2018-07-23 11:42:52 | 1年 | Windows | 单机版 |
| 1397****925 | 2017-03-29 10:56:29 | 1年 | Windows | 单机版 |
| 1397****925 | 2017-03-29 10:56:26 | 1年 | Windows | 单机版 |

 加入购物车成功!
加入购物车成功!
